(1).png)

拜占庭容错系统的设计距今已有几十年,近期区块链解决方案的蓬勃发展也不断地推动着这一主题相关研究的开展。虽然已有大量文献对提高共识系统的可靠性、鲁棒性和可恢复性进行了探讨研究,但针对具有一区块最终确认性的状态机复制机制而言,可用于解决大规模行业案例的相关研究却很少。本文除了可作为一种教学材料之外,也可作为在区块链生态中使用拜占庭容错代理通信问题的科学参考资料。
委托拜占庭容错: 技术细节、挑战和前景
本小节是社区黄皮书:由社区驱动的NEO区块链技术规范,其中的一部分。
针对部分同步和完全异步的拜占庭容错系统 (Hao et al. 2018; Duan, Reiter, and Zhang 2018; Miller et al. 2016)的相关研究文献有很多; 但是能真正应用于真实的不同种类的去中心化应用智能合约(SC)场景的研究却很少。值得注意的是,与涉及状态机复制(Schneider 1990)的智能合约交易持久化需求相比,更新存储状态的应用程序会带来不一样的挑战。此外,要考虑的第二个重要事实与账本信息更新后的确定性有关。终端用户、商家和交易所都希望能明确地知悉他们的交易是否已得到处理或者是否有可能被回退。与先前文献中的大部分研究不同,NEO区块链在第一层网络上提出了一种具有一区块最终确认性的共识机制 (达鸿飞,张铮文 2015)。除了在实际案例应用中广为人知的优势之外,这个特性也带来了一些额外的限制、漏洞和挑战。
[1]参见
本技术材料的目的是强调从经典的实用拜占庭容错机制(pBFT)到当前NEO区块链核心库所采用的委托拜占庭容错机制(dBFT)所做的关键性修改()。此外,文中还描述了一种新颖的数学模型,该模型能够通过离散模型来验证特定的共识行为,而该离散模型能够对实际情景下的共识行为进行建模。本文在强调当前NEO共识机制的积极方面的同时,也旨在指出可能存在的缺陷以及未来的研究和发展方向。后者可以通过将NEO的需求及其新颖的理念与文献中众所周知的一些研究相结合来实现。
本文档的其余部分组织如下。1.1节对经典的PBFT机制的相关背景作了简要的介绍。1.2节描述了为实现NEO dBFT机制而对文献所做的一些关键性修改。1.3节详细介绍了当前对于NEO dBFT机制的最新讨论,并提供了相关伪代码和流程图。最后,1.9节提出了一种基于线性整数规划的新型数学规划模型,该模型对最优的攻击者进行建模,并在最坏的情况下对网络进行测试并验证其局限性。
实用型BFT背景
Miguel Castro和Barbara Liskov(参见图1)在其论文 “实用型拜占庭容错” (Castro and Liskov 1999)中首次提出了实用型BFT的概念。

图1:图灵奖获得者Barbara Liskov, 2010. 维基百科CC BY-SA 3.0
给n=3f+1定个状态机的副本,状态机由主节点和备份节点组成, 所给出的算法可以确保网络的活跃性和安全性,假定发生故障或拜占庭的节点数不超过f。
[1]拜占庭指的是任意的行为,由Leslie Lamport等人在论文“拜占庭将军问题”中提出。
•安全性可以保证所有进程将以原子操作的方式进行,即要么在所有的节点上执行,要么整体都回退。由于进程的确定性(已经在所有节点上执行),这种可能性是存在的,总的来说,这种可能性也同样存在于NEO网络和区块链协议。
•活跃性保证网络不会停止(除非拜占庭节点数超过f),通过使用一种称为“更改视图”的机制,允许在可能发生拜占庭时将备份节点切换成主节点。通过使用超时机制,并在每个视图上成倍地增加延迟时间,PBFT机制可以防止恶意网络延迟的攻击,这种网络无法无限期地运作。在当前的公式中,假定当前的视图编号为n,则将产生区块的周期时间t左移n位后所得到的结果即超时发生的时间,例如:
– 产生区块的周期为15秒: 15<< 1为30s(视图编号为1);15<< 2为60s;15<< 3为120s;15<< 4为240s。
– 产生区块的周期为1秒: 1<< 1 为2s;1 << 2为4s;1<< 3为8s;1<< 4为16s。
基于PBFT机制的网络假定“可能无法传递消息、延迟消息、复制消息或无序地传递消息”。同时使用公钥加密对副本进行身份验证,对于NEO 的dBFT算法而言也是如此。由于算法不依赖同步来保证安全性,因此必须依赖于同步来保证活跃性。对于拜占庭协议(Bracha和Toueg 1985)而言,节点数为3f+1这一设定具有最佳的弹性,其中恶意节点数不超过f。
PBFT正确性的确保主要分为三个阶段:预准备、准备和确认。
•在预准备阶段,主节点会发送一个序列号k以及消息m和签名摘要d。如果签名正确,k是有效间隔,并且备份节点i没有接受过相同k值和相同视图下的预准备信息,那么i将进入预准备阶段。
•进入预准备阶段后,备份节点将全网范围内广播一条准备消息(包括向主节点发送广播),并且对于同一个视图而言,当节点收到与本地预备阶段相匹配的准备消息条数不少于2f时,则表明该节点已经处于准备阶段。因此,对于给定的视图,非故障的复制节点已经就请求的整体顺序达成一致。一旦2f+1个非故障节点准备就绪,网络就可以进入确认阶段。
•每个确认阶段的复制节点会广播一条确认消息,一旦节点i收到2f+ 1条确认信息,则表明该节点已经处于本地已确认(committed-local)阶段。最终,即使视图发生更换,具有本地已确认节点的系统也会完成确认。
PBFT机制认为客户端直接与主节点进行交互并广播消息,同时接收来自2f+ 1个节点的独立响应以便向前推进(执行下一个操作)。NEO区块链也存在类似的情况,其中信息通过点对点的网络进行传播,但是在NEO区块链网络中,共识节点的位置是未知的(为了防止直接延迟攻击和拒绝服务)。在PBFT中,客户端会在不同的时间戳上提交原子且独立的操作,这些操作是独立处理和发布的。而NEO区块链则不同,共识节点必须将交易分组成批,每个组称为一个区块,并且由于分组方式的不同(即对交易的不同组合),可能导致在同一区块高度上存在数千个有效区块。因此,为了保证区块的最终确定性(即对于给定的区块高度,有且只有一个区块),我们不得不考虑“客户端”(区块提议者)也发生故障的情况,而PBFT并没有考虑到这一点。
[1]这一点在论文“具有单故障节点的分布式系统无法达成共识”中得到了证明。
[1]NEOdBFT 2.0也包含三个阶段,命名上略有更改:准备请求,准备响应和确认[1]一种特殊的技术,可以避免因故障而耗尽序列号空间
关键性修改
上一小节我们强调了PBFT和dBFT的一些区别:
•终端用户和种子节点的一区块最终确定性;
•在过程的不同阶段使用加密签名,以免暴露当前区块的节点确认;
•能够基于区块头的信息共享产生区块(交易通过独立的同步机制进行共享和存储);
•通过禁止确认阶段后的视图更改,避免重复暴露区块签名;
•再生机制可恢复故障节点,无论是在本地硬件还是网络P2P共识层。
详细说明
dBFT共识机制本质上是一个状态机,其状态转换依赖于循环模式 (定义主节点/备份节点),也依赖于网络消息。
状态
dBFT有以下几个状态:
•Initial:状态机初始状态
•Primary:依赖于区块高度和视图数量
•Backup:如果不是主节点,则为true,否则为false
•RequestSent:如果区块头请求已发送,则为true,否则为false (在dBFT2.0中已被删除,因为代码会跟踪所有准备签名,并合并为RequestSentOrReceived)
•RequestReceived:如果区块头请求已接收,则为true,否则为false(在dBFT2.0中已被删除,因为代码会跟踪所有准备签名,并合并为RequestSentOrReceived)
•SignatureSent:如果签名已发送,则为true,否则为false (在dBFT 2.0中已被删除,因为新增的确认阶段会携带签名)
•RequestSentOrReceived:如果收到有效的主节点签名,则为true,否则为false(在dBFT2.0中引入)。
•ResponseSent:如果区块头确认已发送,则为true(在dBFT2.0中引入:内部状态,仅用于出块节点触发共识OnTransaction事件)
•CommitSent:如果区块签名已发送,则为true(该状态仅在dBFT2.0中引入,并替换了SignatureSent)
•BlockSent:如果区块已发送,则为true,否则为false
•ViewChanging:如果已触发视图更改机制,则为true,否则为false
•IsIecovery:如果接收到并正在处理一个有效的恢复信息,则为true(在dBFT2.0中引入:内部状态)
第一版的dBFT将这些状态显式地作为标志进行处理 (ConsensusState的枚举值)。但是,dBFT 2.0可以隐式地处理这些信息,因为它会对准备签名和状态恢复机制进行跟踪。
流程图
图2显示了在每个共识节点上进行复制的状态机 (本小节中术语副本/节点/共识节点可视为同义词)。对于区块链上给定的区块高度H,状态机副本的执行流程从Initial状态开始。设T为标准的出块时间(15秒); v是当前的视图编号(从v= 0开始); exp(j)设置为2j; i为共识索引; R为共识节点总数。这个状态机可以表示为一个时间自动机(Alur和Dill 1994),其中C表示时间变量,操作(C条件)? 表示时间转换 (C:=0即重置时间)。虚线表示显式地依赖于超时行为的状态转换,为了清楚起见使用不同格式加以表示。同时假定状态转换按照各状态出现的顺序进行。例如:
(C >= 5)?
A
(C >= 7)?
B
时间C超过5s时,区块状态会转换到状态A,时间C超过7s时,区块状态会切换到B。该状态机能够更为准确地对dBFT 2.0的实现原理加以描述。
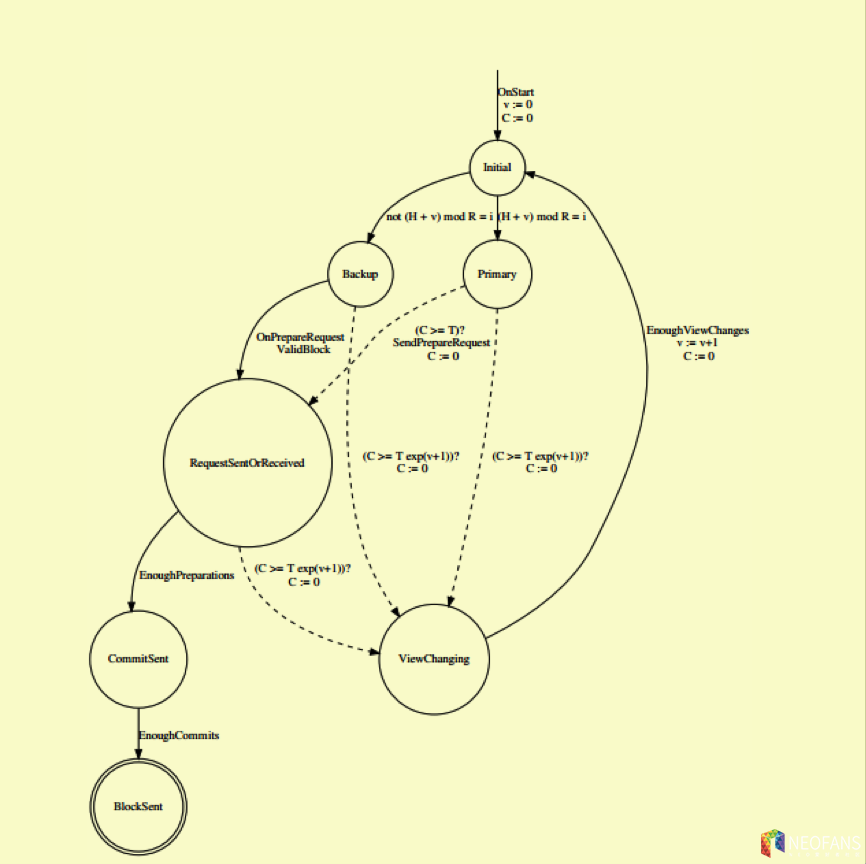
图 2: 给定区块高度下的dBFT 2.0状态机
在图2中,共识节点从Initial状态开始,且视图编号初始值为v= 0。给定H和v,每一轮共识会使用以下公式检测当前节点i是否为主节点:(H+v)modR=i(否则设置为复制节点)。如果当前节点为主节点,则T秒后进入SendPrepareRequest状态(选择交易并创建新的提议块)并再次转换到RequestSentOrReceived状态。如果该节点是复制节点,则需要等待OnPrepareRequest状态。时钟到期后,节点可能会进入ViewChanging状态,这可以在主节点出现故障时保证网络的活跃性。然而,因为该节点已经确认了特定的区块(因此它不会为该高度上的任何其他区块提供签名, CommitSet状态可以保证不会发生视图的更改。由于会影响网络的活跃性,因此状态机提出了一个恢复过程(参见图3)。EnoughPreparations,EnoughCommits和EnoughViewChanges取决于是否有超过拜占庭级别M的足够的有效响应(即不超过最大故障节点数f)。在2.0版本之后,T表示为节点接收到的最后一个区块的时间,而不是前一个区块头被签名时的时间戳。
区块确定性
在共识层级别中的区块确定性由等式(1)中的条件确定,其定义了对于给定的区块高度ℎ,以及任意的出块周期t,不会存在两个不同的区块。
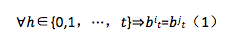
总之,区块确定性使得对于状态机复制(SMR)而言客户不必验证大多数的节点共识。从这个意义上讲,种子节点可以直接追加所有由协议定义的具有真实签名的区块(即M=2f+ 1)。正如当前NEO dBFT算法所描述的,所需的最少签名数是拜占庭将军问题(Lamport,Shostak和Pease 1982)中所定义的2f + 1,其f=1/3×N是网络协议所允许的拜占庭节点的最大个数。
多区块签名曝光
版本检测故障
2017年在NEO区块链网络的实际运行中曾发生过区块散列阻塞分叉的情况。特别地,造成这种现象的原因以下两个由主节点所选择的区块的属性:
•不同的交易集合;
•区块Nonce。
特别地,在没有确认阶段时,NEO dBFT 1.0版本简单地实现了pBFT算法。
但是,在极少数情况下,给定的节点可以接收到持久化一个区块所需的M个签名,然后突然断开与其他节点的连接。这个时候其他节点可以检测到通信的缺失(以及它们之间的其他故障)并生成一个新的区块。除了会破坏区块确定性之外,这个问题可能会终止共识节点以及任何其他客户端的运行,这些客户端会持久化一个没有得到大多数共识节点(CN)共识的区块。此外,在更为少见的情况下,当其他节点具有不同的区块散列时,x个节点可以接收到一个给定的区块,其中$f + 1 <x <M $,从而造成整个网络的崩溃,最终不得不手动进行维护。
值得注意的是,即使在没有超时机制的异步共识中,如果没有对Nonce以及待插入到区块中的交易进行定义,也可能导致问题的产生。这一真实的事件激发了一些关于共识的新颖见解的产生,其中涵盖了由于网络引起的这种“自然”问题以及在真实的拜占庭节点中额外的安全性考量。
带有更换视图出块的确认阶段
考虑到在确认阶段也可能发生上述故障,所以应该对节点加以验证,从而可以阻塞节点而不会重复暴露它的签名。另一方面,如果恶意节点试图保存签名并执行某些特定的操作(如存储信息而不共享信息),也可能发生其他类型的攻击。
就这点而言,自然而然会出现以下这种可能性:
•发送区块头的签名后锁定视图更换(NEOdBFT 2.0后实现了该功能)。这意味着那些被该区块所确认的节点不会对其他提议的区块进行签名。
另一方面,由于节点需要遵守相应的协议,再生策略似乎是必需的。我们将此定义为不知疲倦的矿工问题,定义如下:
该议长是一名地质工程师,正在寻找一个可以挖掘氪石的地方;
他提议了一个地理位置(待挖掘的地理坐标);
团队(M)的大多数成员对该坐标达成了共识(带有他们的签名)并签署了合约同意开始挖掘;
挖掘的时间:他们会不停地挖掘,直到他们找到氪石(在发现氪石前不会去任何其他地方进行挖掘)。氪石是一种无限可分的晶体,因此,一旦有人挖掘到氪石,他就可共享以便所有人都能拥有一块氪石从而履行完他们的合约(3);
如果有人死亡了,当有其他人加入时,他将看到先前签署的协议,并自动开始挖掘(再生策略)。其他小部分人也会遇到相同的问题,可以通过隐藏的信息来告知他们也应该进行挖掘。
该策略在最大故障节点数为f的限制下保证了dBFT算法的强度。此外,生存/再生策略也增强了系统的鲁棒性。
再生
恢复/再生机制用于对给定的丢失部分历史数据的故障节点进行响应。此外,它还在本地进行了数据备份,从而可以在发生硬件故障时恢复节点。这种本地级别的安全性(可以看作是硬件故障安全性)是至关重要的,可减少有意设计的恶意攻击所带来的影响。
从这个意义上讲,如果节点发生故障后又恢复运行,它会自动将change_view设置为0,这意味着该节点已经恢复并希望通过其他节点恢复历史数据。因此,它可能接收一个有效负载,使其能够验证大多数节点的共识并返回开始实际操作,帮助它们对当前正在处理的区块进行签名。
根据这些要求,dBFT 2.0列举了一系列不同的情况,其中节点可以恢复其先前的状态,二者都是网络或自身已知的。因此,目前恢复场景包括:
•重播ChangeView消息;
•重播主节点的prepareRequest信息;
•重播PrepareResponse消息;
•重播Commit消息。
代码可以恢复以下情况:
•将节点恢复到更高级别的视图;
•将节点恢复到已发送准备请求,但还未收集到足够多的进入确认阶段所需的准备信息的视图;
•将节点恢复到已发送准备请求,同时已收集到足够多的准备信息从而可以进入确认阶段的视图,接下来可转换到CommitSent状态;
•将确认签名共享到已确认的节点(激活CommitSent标志)。
图3总结了由恢复机制引导的一些当前状态,这些状态目前由接收到视图更换请求的节点发送。恢复负载由接收到ChangeView请求的节点发送,且节点数不超过f。当前根据负载发送方和本地当前视图的编号进行选择。值得注意的是,OnStart事件会在编号为0的视图处触ChangeView事件,以便与其他节点进行通信,告知其初始活动及其可接收任何恢复负载的状态。这么做的原因是,可以让启动较晚的节点发现网络已经处于某些高级状态。
不同于reResponse状态,这里的内部状态IsRecovering是为了简化Recover消息可能带来的影响。从这个意义上说,在不失一般性的情况下,指向它的箭头可以直接与它指出的箭头相连。
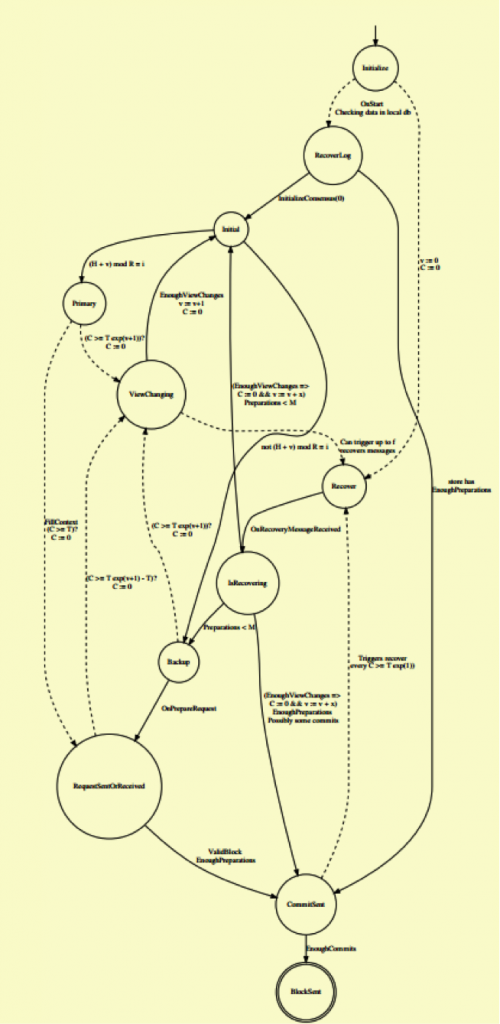
图 3: 带有恢复机制的dBFT 2.0状态机
可能的故障
单纯的网络故障
可能场景:
•多达f个节点延迟消息;
•至多有f个节点会由于硬件故障或者软件问题而崩溃
混合型恶意拜占庭故障
首先,拜占庭式攻击的设计应确保节点永远无法证明这是一次攻击。否则,NEO持有者将重新审视此类行为,并投票支持其他节点。此外,加入给定协作网络的节点拥有身份或权益。如果有人能够检测到这种恶意行为,那么,该节点将“自动”(通过当前的投票系统或可设计的自动机制)从网络中删除。
•至多有f个节点会延迟消息;
•至多有f个节点会发送不正确的信息(由于可以揭示恶意行为,所以这种情况不太可能发生);
•至多有f个节点会尝试为策略场景保留正确的信息。
针对BFT区块链协议的故障和攻击的MILP模型
我们提出了一个针对BFT区块链协议的故障和攻击的MILP模型,该模型针对dBFT的具体情况进行了设计,也适用于其他那些不太特殊的情况。
由于dBFT最近刚更新到2.0版本,所以当前的模型还没有完全完成。完成后,它将包括一些使用数学编程语言(AMPL)建模的基准测试结果,目前正在开发中,可参见:
数学模型
参数:

变量:


目标函数:
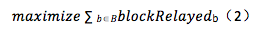
攻击者可以控制f个副本,但其他M个副本必须遵循dBFT算法。攻击者可以为任意消息选择任意延迟时间(最大模拟时间为|T|)。如果它想要关闭整个网络,就不能再产生任何区块,并且目标函数值将为零(可能的最小值)。因此,攻击者将尝试以巧妙的方式来操纵延迟时间从而最大化所生成的区块数。如等式(2)所示,目标函数的值域为[0,|B|]。
限制:





示例



致谢
dBFT 2.0背后的关键思想和开发主要由张铮文指导,而在Github上的开放式讨论中,也有很多来自社区成员的宝贵贡献,感谢大家花费宝贵的时间对BFT理念进行讨论并提出改进建议。我们也感谢为解决这些挑战性问题而不断尝试,并最终对算法进行实现的开发人员。为此,真诚地感谢那些为实现算法而做出贡献的人: jsolman、shargon、longfei、tog、edge等人。
赞





.png) 468
收藏
468
收藏