(1).png)
作者:joohhnnn
opstack是如何从Layer1中派生出来Layer2的
在阅读本文章之前,我强烈建议你先阅读一下来自optimism/specs中有关派生部分的介绍(source[2])
如果你看完这篇文章,感到迷茫,这是正常的。但是还是请记住这份感觉,因为在看完我们这篇文章的分析之后,请你回过来头再看一遍,你就会发现这篇官方的文章真的很凝练,把所有要点和细节都精炼的阐述了一遍。
接下来让我们进入文章正题。我们都知道layer2的运行节点是可以从DA层(layer1)中获取数据,并且构建出完整的layer2区块数据的。今天我们就来讲解一下这个过程中是如何在codebase中实现的。
你需要有的问题
如果现在让你设计这样一套系统,你会怎么设计呢?你会有哪些问题?在这里我列出来了一些问题,带着这些问题去思考会帮助你更好的理解整篇文章
当你启动一个新节点的时候,整个系统是如何运行的?
你需要一个个去查询所有l1的区块数据吗?如何触发查询?
当拿到l1区块的数据后,你需要哪些数据?
派生过程中,区块的状态是怎么变化的?如何从
unsafe变成safe再变成finalized?官方specs中晦涩的数据结构
batch/channel/frame这些到底是干嘛的?(可以在上一章03-how-batcher-works章节中详细理解)
什么是派生(derivation)?
在理解derivation前,我们先来聊一聊optimism的基本rollup机制,这里我们简单以一笔l2上的transfer交易为例。
当你在optimism网络上发出一笔转账交易,这笔交易会被"转发"给sequencer节点,由sequencer进行排序,然后进行区块的封装并进行区块的广播,这里可以理解为出块。我们把这个包含你交易的区块称为区块A。这时的区块A状态为unsafe。接下来等sequencer达到一定的时间间隔了(比如4分钟),会由sequencer中的batcher的模块把这四分钟内所有收集到的交易(包括你这笔转账交易)通过一笔交易发送到l1上,并由l1产出区块X。这时的区块A状态仍然为unsafe。当任何一个节点执行derivation部分的程序后,此节点从l1中获取区块X的数据,并对本地l2的unsafe区块A进行更新。这时的区块A状态为safe。在经过l1两个epoch(64个区块)后,由l2节点将区块A标记为finalized区块。
而派生就是把角色带入到上述例子的l2节点当中,通过不断的并行执行derivation程序将获取的unsafe区块逐步变成safe区块,同时把已经是safe的区块逐步变成finalized状态的一个过程。
代码层深潜
hoho 船长,让我们深潜?
获取batcher发送的batch transactions的data
我们先来看看当我们知道一个新的l1的区块时,如何查看区块里面是否有batch transactions的数据
在这里我们先梳理一下所需要的模块,再针对这些模块进行查看
首先要确定下一个l1的区块块号是多少
将下一个区块的数据解析出来
确定下一个区块的块号
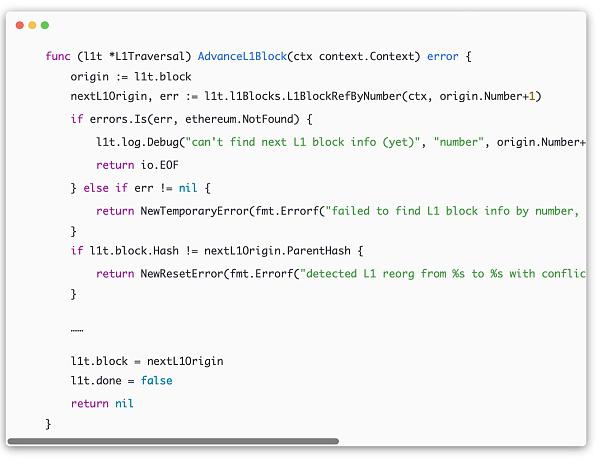
op-node/rollup/derive/l1_traversal.go
通过查询当前origin.Number + 1的块高来获取最新的l1块,如果此块不存在,即error和ethereum.NotFound匹配,那么就代表当前块高即为最新的区块,下一个区块还未在l1上产生。如果获取成功,将最新的区块号记录在l1t.block中
将区块的data解析出来
op-node/rollup/derive/calldata_source.go
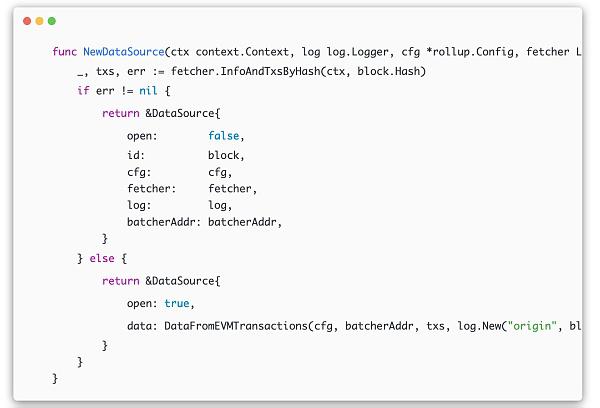
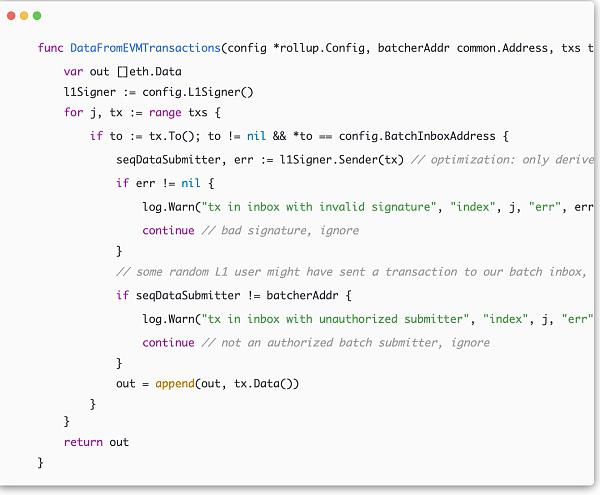
首先先通过InfoAndTxsByHash将刚才获取的区块的所有transactions拿到,然后将transactions和我们的batcherAddr还有我们的config传入到DataFromEVMTransactions函数中,
为什么要传这些参数呢?因为我们在过滤这些交易的时候,需要保证batcher地址和接收地址的准确性(权威性)。在DataFromEVMTransactions接收到这些参数后,通过循环对每个交易进行地址的准确性过滤,找到正确的batch transactions。
从data到safeAttribute,使unsafe的区块safe化
在这一部分,首先会将上一步我们解析出来的data解析成frame并添加到FrameQueue的frames数组里面。然后从frames数组中提取一个frame,并将frame初始化进一个channel并添加到channelbank当中,等待该channel中的frames添加完毕后,从channel中提取batch信息,把batch添加到BatchQueue中,将BatchQueue中的batch添加到AttributesQueue中,用来构造safeAttributes,并把enginequeue里面的safeblcok更新,最终通过ForkchoiceUpdate函数的调用来完成EL层safeblock的更新
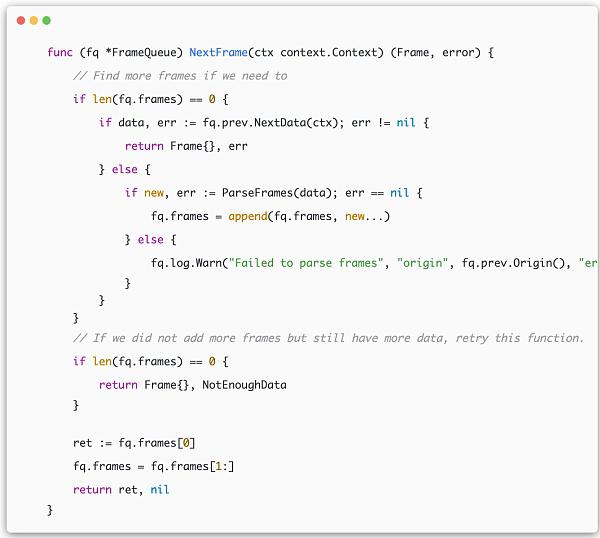
data -> frame
op-node/rollup/derive/frame_queue.go
此函数通过NextData函数获取上一步的data,然后将此data解析后添加到FrameQueue的frames数组里面,并返回在数组中第一个frame。
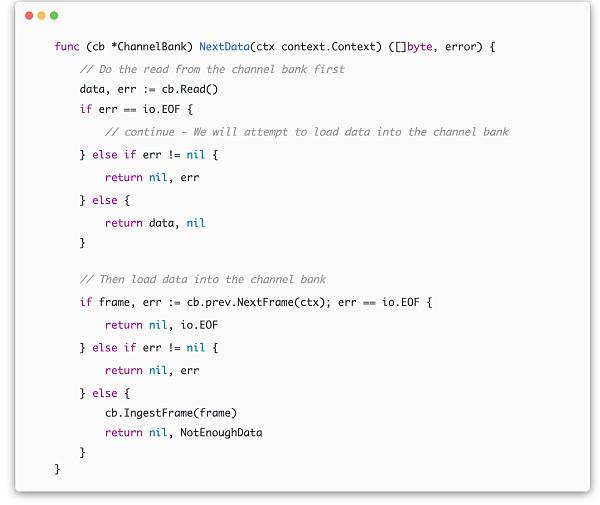
frame -> channel
op-node/rollup/derive/channel_bank.go
NextData函数负责从当前channel bank中读出第一个channel中的raw data并返回,同时负责调用NextFrame获取frame并装载到channel中
channel -> batch
op-node/rollup/derive/channel_in_reader.go
NextBatch函数主要负责将刚才到raw data 解码成具有batch结构的数据并返回。其中WriteChannel函数的作用是提供一个函数并赋值给nextBatchFn,这个函数的目的是创建一个读取器,从读取器中解码batch结构的数据并返回。

*注意❗️在这里NextBatch函数产生的batch并没有被直接使用,而是先加入了batchQueue当中,再统一管理和使用,并且这里的NextBatch实际由 op-node/rollup/derive/batch_queue.go 目录下的func (bq BatchQueue) NextBatch()函数调用
batch -> safeAttributes
补充信息:1.在layer2区块中,区块中的交易中的第一个永远都是一个锚定交易,可以简单理解为包含了一些l1的信息,如果这个layer2区块同时还是epoch中第一个区块的话,那么还会包含来自layer1的deposit交易([epoch中第一个区块示例](https://optimistic.etherscan.io/txs?block=110721915])。
2.这里的batch不能理解为batcher发送的batch交易。例如,我们在这里将batcher发送的batch交易命名为batchA,而在我们这里使用和讨论的命名为batchB,batchA和batchB的关系为包含关系,即batchA中可能包含非常巨量的交易,这些交易可以构造为batchB,batchBB,batchBBB等。batchB对应一个layer2中区块的交易,而batchA对应大量layer2中区块的交易。
op-node/rollup/derive/attributes_queue.go
NextAttributes函数传入当前l2的safe区块头后,将块头和我们上一步获取的batch传递到createNextAttributes函数中,构造safeAttributes。createNextAttributes中我们要注意的是,createNextAttributes函数内部调用的PreparePayloadAttributes函数,PreparePayloadAttributes函数主要负责,锚定交易和deposit交易的。最后再把batch的交易和PreparePayloadAttributes函数返回的交易拼接起来后返回
createNextAttributes函数在内部调用PreparePayloadAttributes
func(aq*AttributesQueue)NextAttributes(ctxcontext.Context,l2SafeHeadeth.L2BlockRef)(*eth.PayloadAttributes,error){
//Getabatchifweneedit
ifaq.batch==nil{
batch,err:=aq.prev.NextBatch(ctx,l2SafeHead)
iferr!=nil{
returnnil,err
}
aq.batch=batch
}
//Actuallygeneratethenextattributes
ifattrs,err:=aq.createNextAttributes(ctx,aq.batch,l2SafeHead);err!=nil{
returnnil,err
}else{
//Clearoutthelocalstateoncewewillsucceed
aq.batch=nil
returnattrs,nil
}
}
func(aq*AttributesQueue)createNextAttributes(ctxcontext.Context,batch*BatchData,l2SafeHeadeth.L2BlockRef)(*eth.PayloadAttributes,error){
……
attrs,err:=aq.builder.PreparePayloadAttributes(fetchCtx,l2SafeHead,batch.Epoch())
……
returnattrs,nil
}
func(aq*AttributesQueue)createNextAttributes(ctxcontext.Context,batch*BatchData,l2SafeHeadeth.L2BlockRef)(*eth.PayloadAttributes,error){
//sanitycheckparenthash
ifbatch.ParentHash!=l2SafeHead.Hash{
returnnil,NewResetError(fmt.Errorf("validbatchhasbadparenthash%s,expected%s",batch.ParentHash,l2SafeHead.Hash))
}
//sanitychecktimestamp
ifexpected:=l2SafeHead.Time+aq.config.BlockTime;expected!=batch.Timestamp{
returnnil,NewResetError(fmt.Errorf("validbatchhasbadtimestamp%d,expected%d",batch.Timestamp,expected))
}
fetchCtx,cancel:=context.WithTimeout(ctx,20*time.Second)
defercancel()
attrs,err:=aq.builder.PreparePayloadAttributes(fetchCtx,l2SafeHead,batch.Epoch())
iferr!=nil{
returnnil,err
}
//weareverifying,notsequencing,we'vegotalltransactionsanddonotpullfromthetx-pool
//(thatwouldmaketheblockderivationnon-deterministic)
attrs.NoTxPool=true
attrs.Transactions=append(attrs.Transactions,batch.Transactions...)
aq.log.Info("generatedattributesinpayloadqueue","txs",len(attrs.Transactions),"timestamp",batch.Timestamp)
returnattrs,nil
}
safeAttributes -> safe block
在这一步,会先engine queue中的safehead设置为safe,但是这并不代表这个区块是safe的了,还必须通过ForkchoiceUpdat在EL中更新
op-node/rollup/derive/engine_queue.go
tryNextSafeAttributes函数在内部判断是否当前safehead和unsafehead的关系,如果一切正常,则触发consolidateNextSafeAttributes函数来把engine queue中的safeHead 设置为我们上一步拿到的safeAttributes构造出来的safe区块,并将needForkchoiceUpdate设置为true,触发后续的ForkchoiceUpdate来把EL中的区块状态改成safe而真正将unsafe区块转化成safe区块。最后的postProcessSafeL2函数是将safehead加入到finalizedL1队列中,以供后续finalied使用。
func(eq*EngineQueue)tryNextSafeAttributes(ctxcontext.Context)error{
……
ifeq.safeHead.Numberreturneq.consolidateNextSafeAttributes(ctx)
}
……
}
func(eq*EngineQueue)consolidateNextSafeAttributes(ctxcontext.Context)error{
……
payload,err:=eq.engine.PayloadByNumber(ctx,eq.safeHead.Number+1)
……
ref,err:=PayloadToBlockRef(payload,&eq.cfg.Genesis)
……
eq.safeHead=ref
eq.needForkchoiceUpdate=true
eq.postProcessSafeL2()
……
returnnil
}
将safe区块finalized化
safe区块并不是真的牢固安全的区块,他还需要进行进一步的最终化确定,即finalized化。当一个区块的状态转变为safe时,从此区块派生的来源L1(batcher transaction)开始计算,经过两个L1 epoch(64个区块后,此safe区块可以被更新成finalzied状态。
op-node/rollup/derive/engine_queue.go
tryFinalizePastL2Blocks函数在内部对finalized队列中区块进行64个区块的校验,如果通过校验,调用tryFinalizeL2来完成engine queue当中finalized的设置和标记needForkchoiceUpdate的更新。
func(eq*EngineQueue)tryFinalizePastL2Blocks(ctxcontext.Context)error{
……
eq.log.Info("processingL1finalityinformation","l1_finalized",eq.finalizedL1,"l1_origin",eq.origin,"previous",eq.triedFinalizeAt)//constfinalityDelayuntypedint=64
//Sanitycheckweareindeedonthefinalizingchain,andnotstuckonsomethingelse.
//Weassumethattheblock-by-numberqueryisconsistentwiththepreviouslyreceivedfinalizedchainsignal
ref,err:=eq.l1Fetcher.L1BlockRefByNumber(ctx,eq.origin.Number)
iferr!=nil{
returnNewTemporaryError(fmt.Errorf("failedtocheckifonfinalizingL1chain:%w",err))
}
ifref.Hash!=eq.origin.Hash{
returnNewResetError(fmt.Errorf("needtoreset,weareon%s,notonthefinalizingL1chain%s(towards%s)",eq.origin,ref,eq.finalizedL1))
}
eq.tryFinalizeL2()
returnnil
}
func(eq*EngineQueue)tryFinalizeL2(){
ifeq.finalizedL1==(eth.L1BlockRef{}){
return//ifnoL1informationisfinalizedyet,thenskipthis
}
eq.triedFinalizeAt=eq.origin
//defaulttokeepthesamefinalizedblock
finalizedL2:=eq.finalized
//gothroughthelatestinclusiondata,andfindthelastL2blockthatwasderivedfromafinalizedL1block
for_,fd:=rangeeq.finalityData{
iffd.L2Block.Number>finalizedL2.Number&&fd.L1Block.Number<=eq.finalizedL1.Number{
finalizedL2=fd.L2Block
eq.needForkchoiceUpdate=true
}
}
eq.finalized=finalizedL2
eq.metrics.RecordL2Ref("l2_finalized",finalizedL2)
}
循环触发
在op-node/rollup/driver/state.go中的eventLoop函数中负责触发整个循环过程中的执行入口。主要是间接执行了了op-node/rollup/derive/engine_queue.go中Step函数
func(eq*EngineQueue)Step(ctxcontext.Context)error{
ifeq.needForkchoiceUpdate{
returneq.tryUpdateEngine(ctx)
}
//Tryingunsafepayloadshouldbedonebeforesafeattributes
//Itallowstheunsafeheadcanmoveforwardwhilethelong-rangeconsolidationisinprogress.
ifeq.unsafePayloads.Len()>0{
iferr:=eq.tryNextUnsafePayload(ctx);err!=io.EOF{
returnerr
}
//EOFerrormeanswecan'tprocessthenextunsafepayload.Thenweshouldprocessnextsafeattributes.
}
ifeq.isEngineSyncing(){
//MakepipelinefirstfocustosyncunsafeblockstoengineSyncTarget
returnEngineP2PSyncing
}
ifeq.safeAttributes!=nil{
returneq.tryNextSafeAttributes(ctx)
}
outOfData:=false
newOrigin:=eq.prev.Origin()
//CheckiftheL2unsafeheadoriginisconsistentwiththeneworigin
iferr:=eq.verifyNewL1Origin(ctx,newOrigin);err!=nil{
returnerr
}
eq.origin=newOrigin
eq.postProcessSafeL2()//makesurewetrackthelastL2safeheadforeverynewL1block
//trytofinalizetheL2blockswehavesyncedsofar(no-opifL1finalityisbehind)
iferr:=eq.tryFinalizePastL2Blocks(ctx);err!=nil{
returnerr
}
ifnext,err:=eq.prev.NextAttributes(ctx,eq.safeHead);err==io.EOF{
outOfData=true
}elseiferr!=nil{
returnerr
}else{
eq.safeAttributes=&attributesWithParent{
attributes:next,
parent:eq.safeHead,
}
eq.log.Debug("Addingnextsafeattributes","safe_head",eq.safeHead,"next",next)
returnNotEnoughData
}
ifoutOfData{
returnio.EOF
}else{
returnnil
}
}
总结
整个derivation功能看似非常复杂,但是你如果将每个环节都拆解开的话,还是能够很好的掌握理解的,官方的那篇specs不好理解的原因在于,他的batch,frame,channel等概念很容易让人迷茫,因此,如果你在看完这篇文章后,仍然觉得还很迷惑,建议可以回过头去再看看我们的03-how-batcher-works。
参考资料
[1]
joohhnnn: https://learnblockchain.cn/people/4858
[2]
source: https://github.com/ethereum-optimism/optimism/blob/develop/specs/derivation.md#deriving-payload-attributes
[3]
第一章: https://learnblockchain.cn/article/6589
[4]
第二章: https://learnblockchain.cn/article/6755
[5]
第三章: https://learnblockchain.cn/article/6756
[6]
第四章: https://learnblockchain.cn/article/6757
[7]
第五章: https://learnblockchain.cn/article/6758
赞





.png) 229
收藏
229
收藏