iOS版下载
iOS版下载
 安卓版下载
安卓版下载




原文标题:《Web3 数据经济》
影子数据经济
《经济学人》2017 年 5 月刊的封面故事将数据定义为「世界上最具价值的资源」。在数据背后,谷歌、脸书和其它少数公司共计投入逾十亿美元的市场资本,开展相关业务。对于他们来说,数据就是金钱:更多的数据意味着更完善的人工智能模型、受众定位更准确的广告、更可观的广告点击量和更丰厚的收益。逐利的目光又重新回到了数据身上。
我们拥有的数据经济却是一种影子数据经济。这种数据经济是不透明的:谷歌等公司出于竞争原因对数据进行保密,不与外界分享(即所谓的「data silo」)。同时,权力呈现出集中化状态,比如扎克伯格掌握 20 亿用户数据。
我们可以将数据经济转变为一种开放且无需许可的经济吗?这就是海洋协议(Ocean Protocol)所追求的目标。幸运的是,我们已经有了灵感……
货币经济
2005 年,草莓采摘工 Alberto Ramirez 成功申请到一笔贷款,用以购买一套价值 72 万美元的房子,而他的年收入是 1 万 5 千美元。也就是说,他不可能还得清这笔贷款。那他为何能贷款成功呢?正如数据一样:跟着钱走。借贷方赚取了巨额的手续费:他们早就摸清了如何通过信用违约掉期之类的伎俩使「不可能还清」的贷款被评为高质量贷款。
2008 年,这个不切实际的计划如纸牌屋轰然倒塌,导致了数万亿美元的损失。最后是纳税人为此买单。而银行家们净顾着聚拢各自的分红,却对此残局一言不发。
这就是美联储和银行所遭遇的影子货币经济。这种经济是不透明的,同时,权力集中在少数人手中。
但后来我们有了比特币!中本聪明确地指出,金融危机就是 TA 创造比特币的原因所在。比特币引发了区块链运动。而作为该运动一部分的代币经济为货币开辟了新方向:透明且无需许可。
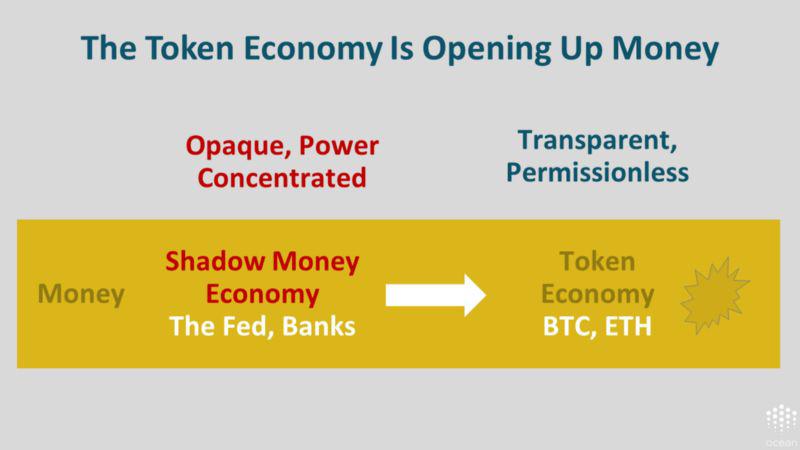
代币经济就是我们的灵感来源。正如我们已经通过区块链运动为货币开辟了新天地一样,让我们也为数据翻开新的篇章吧。
让我们从不透明且权力集中的影子数据经济转型为透明且无需许可的 Web3 数据经济吧。
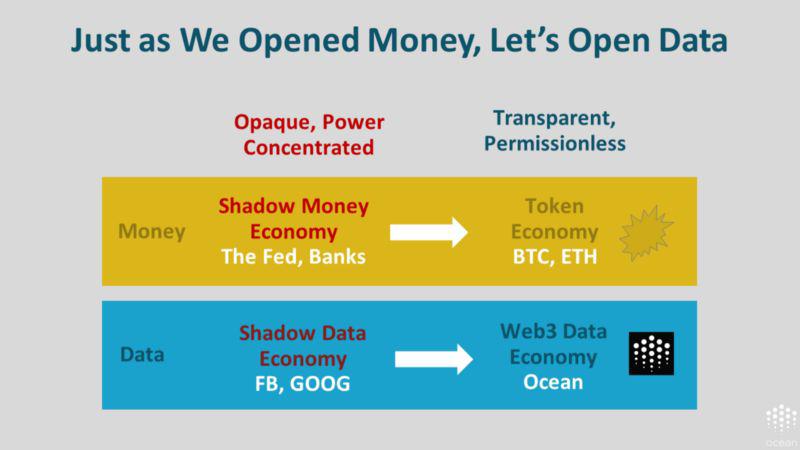
问题在于如何转型?同时,这种转型实际上会呈现出怎样的面貌?出人意料的是,这一切的契机在于人工智能。
迈向开放的数据经济
有了数据,你就可以得到价值。转化过程的关键一步在于人工智能模型。你拥有的数据越多,你的模型就越准确,所获得的收益就越丰厚。人工智能就是关键所在。
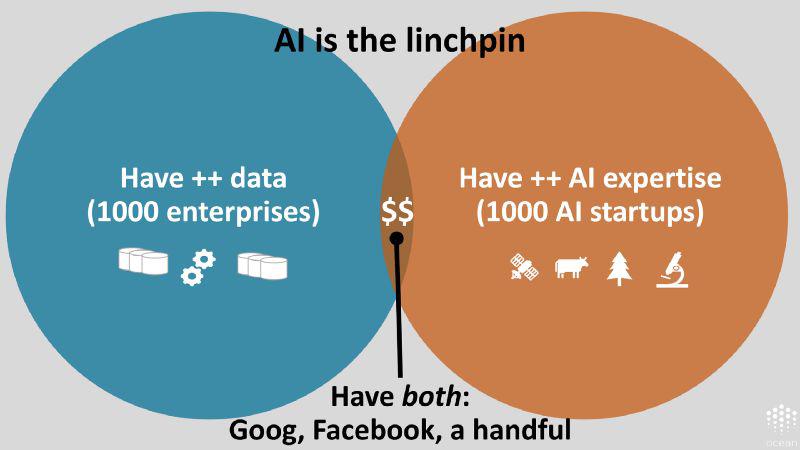
企业、非政府组织和政府拥有大量的数据以及人工智能问题(需求)。人工智能初创公司拥有大量的人工智能专业知识。同时拥有两者的却寥寥无几。
企业(财富 500 强公司)、非政府组织和政府内部的确掌握数以吨计的数据。尽管它们拥有数据,却未掌握人工智能专业知识。它们难以吸引人工智能研究者的加入。为什么呢?因为人工智能专家都去组建自己的初创公司了,他们想通过人工智能赚钱。
同时,相信你也能猜到,这些初创公司开始意识到,他们没有数据!
只有少数公司同时拥有数据和人工智能专业知识,比如谷歌、脸书等。就是这样。这些组织形成的小团体在拢聚所有的价值。人工智能成为了关键一环。
如果我们可以将数据所有者(拥有数据的人)和人工智能所有者(拥有人工智能专业知识且渴望拥有数据的人)联系在一起会怎样呢?
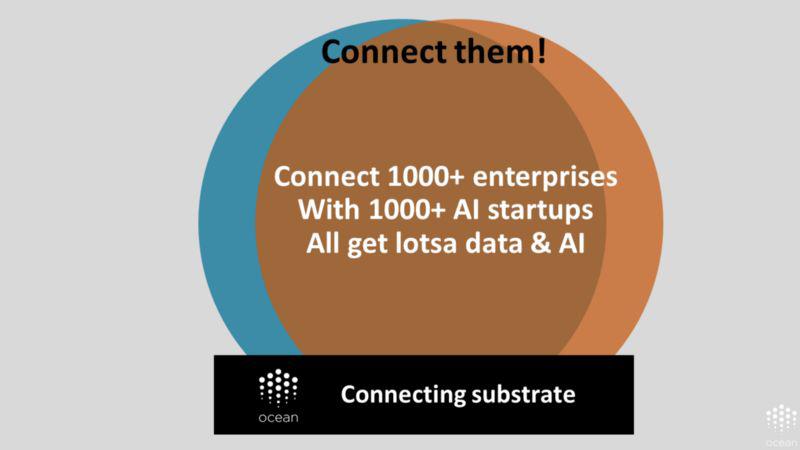
为此,设想我们可以创造一个用于连接这些人群的基础层。这个基础层可以帮助实现人工智能和数据利用机会的均等化。
下面的图片详细展示了这一设想。顶层是主要用户:问题提出者和问题解决者。底层就是上述具备连接功能的基础层。两者之间呢,则是类似于生命体中结缔组织的中间件:与 AI Commons (直译为人工智能公共资源)并存的市场,以及数据科学工具。
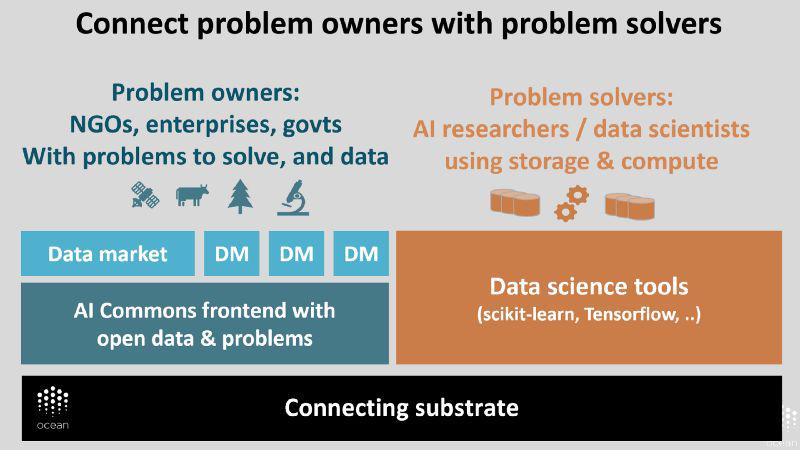 译者注:即需方(左边,同时也是数据供方)和解决方案供方(右边)
译者注:即需方(左边,同时也是数据供方)和解决方案供方(右边)
在问题提出者一侧,政府经常授权开放自身所掌握的数据。其中包括市级政府,直至州或省级政府和国家级政府。联合国机构和其它非政府组织正致力于数据处理,但是遇到了和企业一样的问题。如上文所述,企业难以获取人工智能专业知识;这项挑战也降临到了政府和非政府组织头上。
就数据而言,需求侧相对容易做起来。人工智能热爱数据。更准确的说法是,数据科学家知道自己的人工智能模型需要尽可能充分地利用外界提供的数据。
因此,真的要让供给侧给力起来。我们采取的方式是让已标价数据和免费数据如阴阳哲学一般保持对立统一。想象一下,拥有几十乃至上百个数据市场,在不同的行业和垂直领域买卖数据,比如汽车业、医学领域等等,以及数据公共资源,那是怎样的情景。同时,除了有价数据,还会出现免费数据,以及鼓励人们提供免费数据的激励机制。如果我们也在公共事业领域提出 AI 问题,加上鼓励解决问题的激励机制,我们就有了 AI Commons。
应用
我们一起来探讨一下 Web3 数据基础层的具体应用。
无人驾驶汽车。无人驾驶汽车有望以更低廉的成本实现更强大的机动性。然而,我们需要降低无人驾驶汽车的事故率。为此,我们需要更多的数据:兰德公司曾计算出我们需要 5000 亿英里的里程数。从个别情况来看,大型汽车制造商计算得出,他们需要 10 到 20 年的时间来获得这个数据量。宝马、通用等公司组建了「MOBI (Mobility Open Blockchain Initiative, 移动开放区块链计划)基金会」(MOBI Foundation),借此汇集数据,目前在利用 Ocean Web3 数据基础层。

健康。癌症如果早发现早治疗的话,可以挽救生命。我的一位朋友搭建了用于预测癌症的遗传编程模型。如果可以拥有一个 100 个样本点的数据集,他就很满意了,这也意味着他的模型预测能力还是很差的。另外,由于数据收集方面的差异(比如样本在测量之前呆在培养皿中的时长),每个医院站点都存在偏差。如果我们可以在获取来自 10 家、100 家或更多家医院的数据并建立模型的同时做到保护隐私性会怎么样呢?有一种方法:在产生数据的地方计算,同时利用 Federated Learning (校对注:谷歌开发的一种机器学习模型,特点是将模型下载到本地、在本地提供数据改进模型之后再把新模型上传到云端、与其他人的更新进行整合)在多家医院之间建立模型。
这就是 ConnectedLife 的研究方向,该公司致力于应对帕金森病,他们也再利用 Ocean Web3 数据基础层。
农业。世界经济论坛衍生出来的 Grow Asia 平台致力于为农民提供更多的数据,这样的话,农民可以更加准确地预测施肥量、播种量等。他们利用 Ocean Web3 数据基础层来迭代这个过程。
决策。 对于新的欧洲数据隐私保护规则(欧盟通用数据保护条例,GDPR)而言,决策者是基于当今技术来设计这些规则的。制定政策不是容易的事情。其中部分规则可能比较严厉,但是也大有裨益。但是,想象一下,如果你可以拥有解决隐私问题的更佳选择同时可以从人工智能和数据中获得经济利益,那岂不是可以顺利地完成这项艰难的任务吗。出于此目的,新加坡政府的数据主管部门(资讯通信媒体发展管理局)目前在利用 Ocean Web3 数据基础层进行迭代。

人工智能公共资源。作为「人工智能造福人类(AI for Good)」运动的缩影,去年召开的「人工智能造福人类(AI for Good)」峰会聚集了 40 多个联合国机构,学习如何利用人工智能实现联合国 17 项可持续发展目标(UN 17 Sustainable Development Goals, SDGs)。这些机构的工作人员需要切实解决人工智能相关问题,而且他们有数据。但是,他们联系不到懂得如何解决这些问题的人士,即数据科学家。我们可以通过网络实现一次性连接,或者可以在 Web3 数据基础层中将其向上扩展为人工智能公共资源。

数据经济会呈现怎样的面貌?
上文探讨了实现开放且无需许可的 Web3 数据经济的动机、从货币经济中汲取的灵感、为这种经济打造的数据基础层及其应用。那么这种经济究竟呈现出怎样的面貌呢 ?
启发
我们可以再次回到货币经济来寻求启发。一起来了解一下这种开放、自由的代币经济都由哪些元素组成。(尽管是一个简化的模型,但是可能有用。)
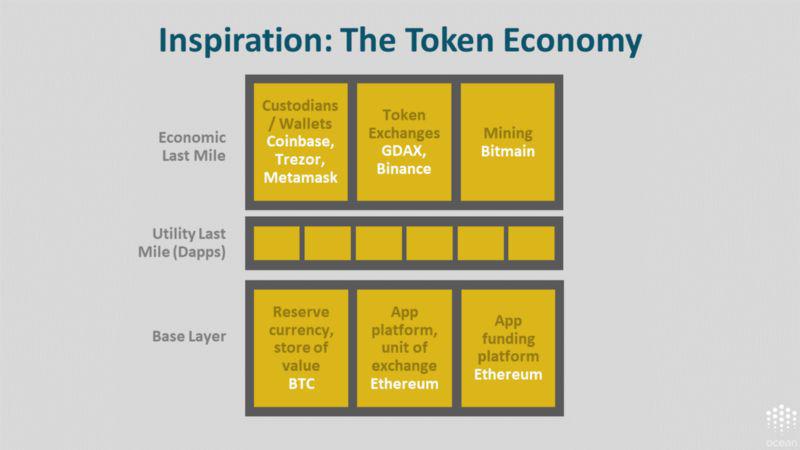
底部是代币经济的基本层。有储备货币或价值储藏手段:比特币。有应用平台或者交易媒介,比如以太坊。最后还有应用融资平台:以太坊。最近还出现了未来代币简单协议(Simple Agreement for Future Tokens, SAFTs)。
中部是效用的「最后一英里」。这些是去中心化应用。
顶部是经济层的「最后一英里」。其中包括管理工具 / 钱包,比如 Coinbase、Tresor 和 Metamask;还包括代币交易所,比如 GDAX 和 Binance (币安);最后包括挖矿,比如 Bitmain (比特大陆)。
如果数据经济像代币经济一样(至少基本一致)会如何呢?我们可以通过下面的图片构想一下。
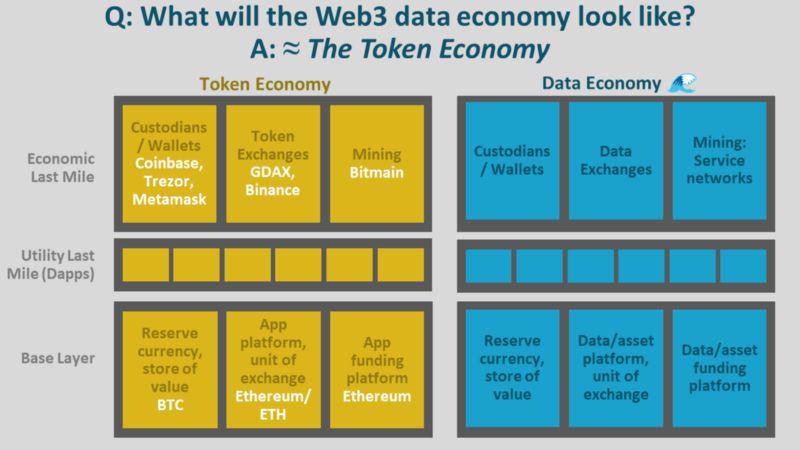
我们可以对照设想出储备货币、交换单位、数据或资产融资平台以及效用和经济的「最后一英里」。
Web3 数据经济的组成元素
接下来,我们如何来实例化这个数据经济呢?我们需要填充所有的蓝框。我们来根据海洋协议现有 (但是可能变更) 的设计探究出一种实现途径吧。
结合质押曲线(bonding curve),用户可以把赌注押在数据资产上(详情)。这用作表示数据集 X 的相关性。你在 X 上押的赌注越多,表示你认为它的相关性或普及性会越高、因此为其提供资金可以期望获得更多的奖励(校对注:原文为「block reward」,区块奖励)。
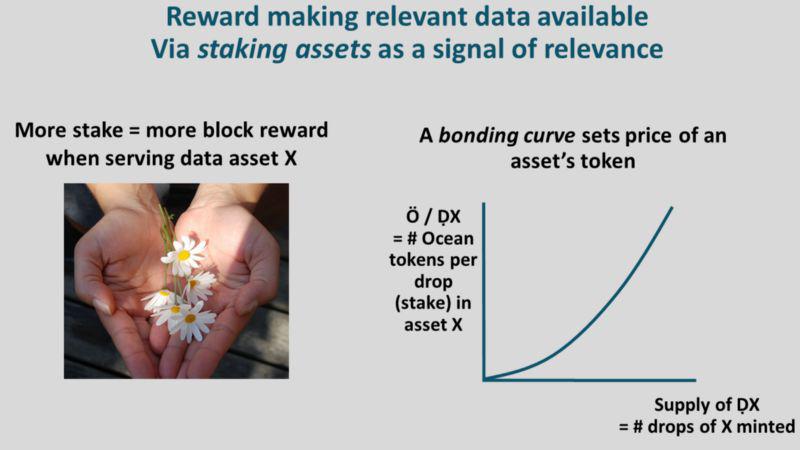
质押曲线(BC)是自动化的做市商,即总是在以一定的价格购买或出售代币,达到交换的目的。对于数据资产 X 来说,BC 开始出售被称为 DX (drops of X)的代币,以交换 Ocean 代币 O。起初 DX 数量为 0,但是一旦有人开始购买 DX,那么 BC 就会铸造更多的代币。DX 代币随着购买量的增加逐渐涨价。如果你出售一些 DX,它们就会被销毁。这就形成了铸造或烧毁代币的一种不间断的循环。
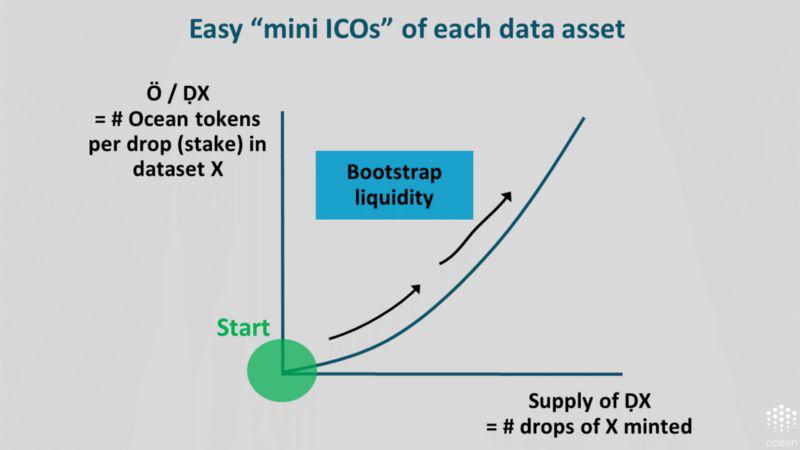
基本层:数据资产融资平台。每当你发布数据资产并初始化质押曲线的时候,你也将启动一次「微型
ICO」。人们可以购买代币,同时每个代币都携有一些从区块奖励中获得预期收入的权利。起初,代币并不存在。但是只要有人开始对上述数据资产下注,就会发行这种数据资产的代币。
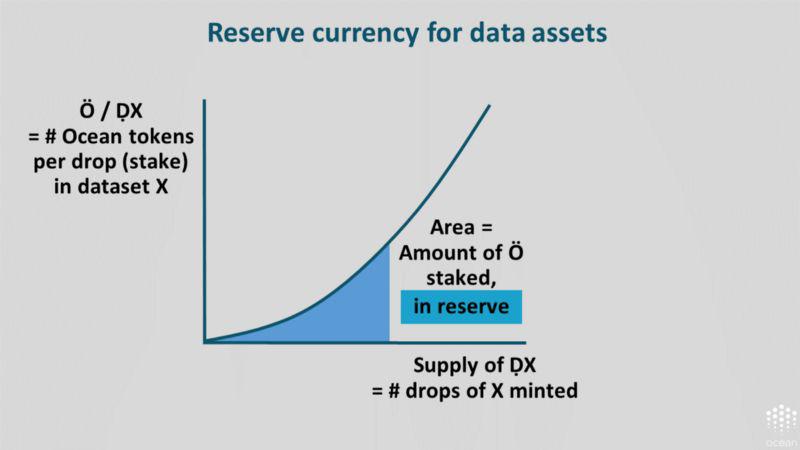
基本层:储备货币。质押曲线具备内置的储备货币行为。曲线下方的区域实际上是一个储备区,用来控制流动资产。在其中一条质押曲线中押的代币越多,你拥有的储备货币就越多。
基本层:交换单位。交易的媒介会从购买和出售数据,以及存储、计算等服务中产生。Web3 数据基础层具备实现上述目的的多种机制。
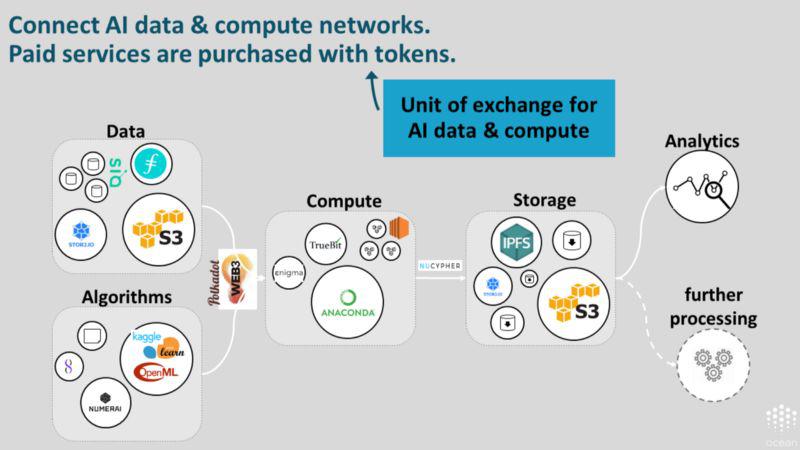
综上所述,Web3 数据基础层在储备货币或价值储存手段、交换单位和融资平台方面实现了数据经济的基本层。
如下图所示,该基本层上部就是经济和效用的「最后一英里」。这里涉及到很多内容,我们来一一介绍。
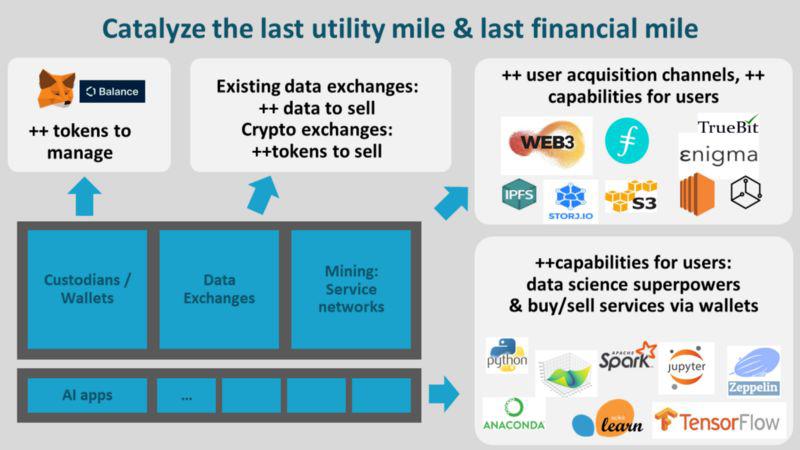
经济的最后一英里:管理员 / 钱包。代币管理可以通过传统的工具实现,比如 Metamask 或
Balance,甚或是专门为数据经济设计的新型钱包。我们认为,在代币经济中,我们目前已经走到代币的长尾阶段(校对注:即单个产品需求量很小但总市值很大的市场)。而在数据经济中,我们可以更多数量级的代币。这可能是 1 万甚或 1 百万个数据集,每个数据集带有自己的代币。届时管理这些数据集的方式想必会很有趣。考虑一下这对于钱包建立者来说是多大的挑战!
经济的最后一英里:数据交易所。现有的中心化数据交易所和去中心化数据交易所可能会发现增加他们来自 Web3 数据基础层的数据供应量是有价值的。区块链代币交易所可能会发现在他们的平台上买卖更多的代币是有利可图的。
经济的最后一英里:服务网络。在 Web3 数据经济中,数据、存储和计算服务的提供者才是真正的「矿工」。它们具备三大潜在效益:成为获取客户的新渠道(这个渠道可能很大);为其客户提供新性能;以及通过奖励为自身及用户带来新收益。
效用的最后一英里。这是数据科学家的新世界:更多的数据、更好的信息源和新的收入机会(详情)。因此,数据科学工具制造者可能会发现,利用 Web3 数据基础层可以帮助他们提供更优质服务。我们也期待用于应对经济和效用最后难关的工具出现有趣的结合,比如兼具内置钱包和数据买卖手段的 Jupyter 笔记本(一种交互式笔记本,支持运行 40 多种编程语言)。个别的笔记本凭借其算法和技术诀窍,可能在数据买卖领域形成新气象!
简而言之,Web3 数据经济可能在很多方面都和代币经济很像。
结论
数据就是金钱。让我们在 Web3 的世界中开启数据的大门吧。我们从影子货币经济迈向了代币经济。数据方面也这么干吧。让我们从影子数据经济迈向透明且无需许可的数据经济,即 Web3 数据经济。